LaunchesOpenAI4d ago

X/Twitter@OpenAIOpenAIlaunchlaunch4d ago
Sol, Terra, and Luna, our GPT‑5.6 family of models, are starting to roll out now in ChatGPT, Codex, and the API. https://t.co/Qri7GdtYs3
View Post
#openai#twitter#x
OpenAI
Compact GPT-5.4 variant that keeps modern reasoning and coding performance at lower latency and cost.
51.8
Quality Score
1254
Arena ELO
Undisclosed
Parameters
256K
Context
Sign in to join the discussion
0
Downloads
0
Likes
Mar 2026
Released
Launches
3
Benchmarks
5
API
1
Research
4
General
4
Recent launch, pricing, benchmark, and API signals linked to this model or its provider.
Models | OpenAI API ChatGPT Home API Docs Guides and concepts for the OpenAI API API reference Endpoints, parameters, and responses Codex Docs Guides, concepts, and product docs for Codex Use cases Example workflows and tasks teams can take on with ChatGPT or Codex Docs Use cases Resources ChatGPT Apps SDK Build apps to extend ChatGPT Workspace Agents Trigger published ChatGPT workspace agents Commerce Build commerce flows in ChatGPT Ads Publish and measure ads in ChatGPT Res
Models | OpenAI API ChatGPT Home API Docs Guides and concepts for the OpenAI API API reference Endpoints, parameters, and responses Codex Docs Guides, concepts, and product docs for Codex Use cases Example workflows and tasks teams can take on with ChatGPT or Codex Docs Use cases Resources ChatGPT Apps SDK Build apps to extend ChatGPT Workspace Agents Trigger published ChatGPT workspace agents Commerce Build commerce flows in ChatGPT Ads Publish and measure ads in ChatGPT Res
View sourceModels | OpenAI API ChatGPT Home API Docs Guides and concepts for the OpenAI API API reference Endpoints, parameters, and responses Codex Docs Guides, concepts, and product docs for Codex Use cases Example workflows and tasks teams can take on with ChatGPT or Codex Docs Use cases Resources ChatGPT Apps SDK Build apps to extend ChatGPT Workspace Agents Trigger published ChatGPT workspace agents Commerce Build commerce flows in ChatGPT Ads Publish and measure ads in ChatGPT Res
View sourceWe audited SWE-Bench Pro, one of the most widely used AI coding benchmarks, and found it no longer reliably measures frontier coding capability. We find 30% of SWE-Bench Pro tasks to be broken, and are retracting our previous recommendation that the research community use it as
We audited SWE-Bench Pro, one of the most widely used AI coding benchmarks, and found it no longer reliably measures frontier coding capability. We find the eval to be saturated at a ~70% noise ceiling, and are retracting our previous recommendation that the research community

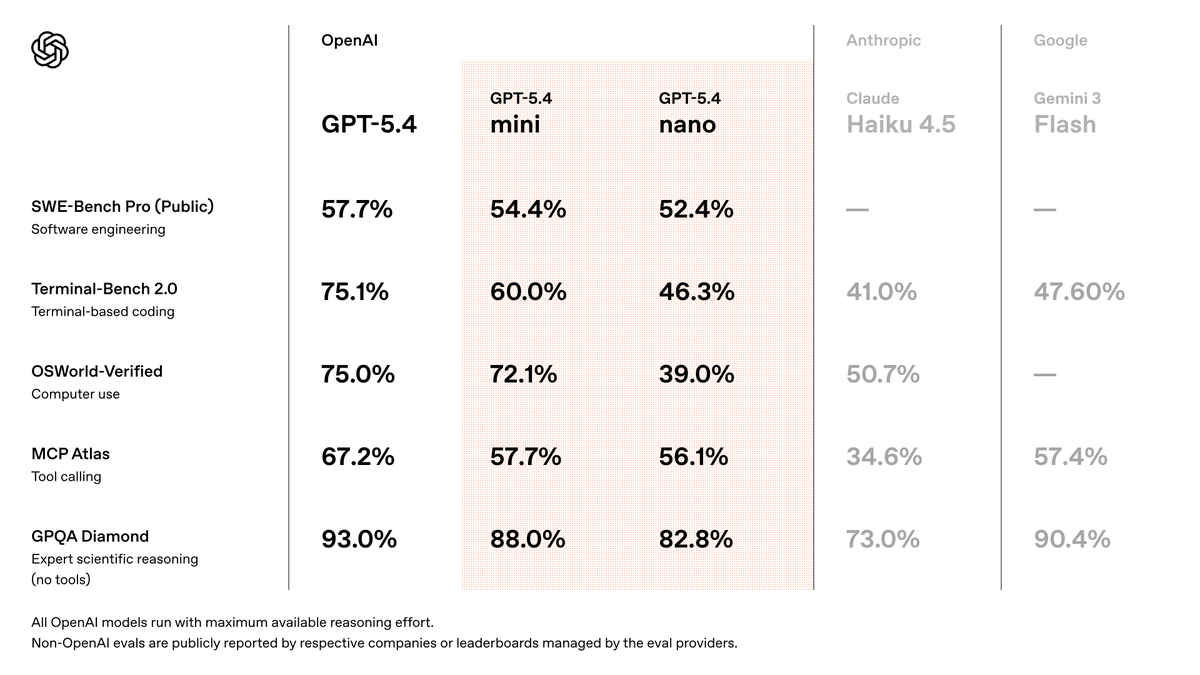
GPT-5.4 mini is available today in ChatGPT, Codex, and the API. Optimized for coding, computer use, multimodal understanding, and subagents. And it’s 2x faster than GPT-5 mini. https://t.co/DKh2cC5S3F https://t.co/sirArgn37L
Current computational approaches for drug design typically focus on generating molecules conditioned on specific targets or general molecular properties, often neglecting the influence of disease context on target behavior and therapeutic outcomes. To address this gap, we introduce DrugGen-2, a novel generative model that designs small molecules conditioned on both disease ontology and target protein sequences. DrugGen-2 was developed by fine-tuning a pre-trained GPT-2 model on a curated dataset of approved drugs linked to their diseases and targets, using a two-step strategy of supervised fine-tuning followed by reinforcement learning via group relative policy optimization (GRPO). This process was guided by reward functions optimizing for chemical validity, novelty, diversity, and high predicted binding affinity. When evaluated on five protein targets relevant to diabetic nephropathy, DrugGen-2 significantly outperformed baseline models (DrugGPT and DrugGen). It demonstrated a superior capacity to generate unique molecules, exhibited greater structural similarity to approved drugs, and achieved improved predicted binding affinities across all targets. Molecular docking analyses further supported these findings, identifying candidate ligands with strong binding potential, including compounds with predicted affinities (-9.917, -9.485, and -9.367) exceeding those of reference drugs such as enalapril for angiotensin-converting enzyme (-8.283). By integrating disease-specific context into molecular generation, DrugGen-2 advances AI-assisted drug discovery, offering a powerful tool for de novo design and drug repurposing that accounts for the complex interplay between diseases and molecular targets.
Repository-level vulnerability reproduction is a demanding software engineering (SE) task: an agent must inspect a codebase, infer the input grammar that reaches a vulnerable path, construct a proof-of-conceptv(PoC), and verify that the crash disappears on the patched build. Recent LLM agents can often execute these steps when the approach is correct, yet they still fail by choosing the wrong strategy. This paper argues that strategy, rather than the full action trajectory, is the right learning unit for such SE agents: it is compact enough to optimize, concrete enough to guide execution, and stable enough to store and reuse across attempts. We present Mastermind, a dual-loop framework that separates transferable strategy learning from task-specific experience. A trainable planner learns reusable vulnerability-reproduction strategies through SFT and milestone-based GRPO, while an experience loop maintains task-local strategy records that guide subsequent attempts. The planner is trained independently of the executor, allowing strategy learning to improve multiple frozen executors without modifying their action-generation capability. We evaluate Mastermind on CyberGym using 260 training tasks and 200 held-out evaluation tasks. With GPT-5.5 as the frozen executor, Mastermind achieves an 84.5% pass rate, outperforming open-book PoC context (60.0%), Best-of-8 sampling (63.0%), and iterative improvement (77.0%). The same planner also improves GPT-5.4 mini and GLM~5.1 from 45.0% and 58.5% to 60.0% and 71.0%. These results demonstrate that learning high-level strategies is an effective and transferable mechanism for improving repository-scale SE agents.
Retrieval for search agents is still inherited from non-agentic information retrieval: a retriever ranks the corpus and the agent reads a small set of returned documents. Recent direct corpus interaction (DCI) work shows that agents can instead interact with the raw corpus through shell tools such as grep and file reads. But unbounded interaction does not scale: every broad shell command is a scan over the whole corpus, and latency degrades sharply as the corpus grows. We argue that the role of retrieval for agentic search is not just to select documents that fit in the LLM context window, but to construct an interaction space: a bounded subset of the corpus the agent can explore with associated tools. Two design consequences follow. The space needs a boundary supplied by retrieval, and the objects within it should be processed for interaction. As a proof of concept, we propose RISE (Retrieving Interaction SpacE): we use BM25 to construct the interaction space; meanwhile, its documents are processed during indexing for shell-style navigation. On BrowseComp-Plus, RISE matches the pure-shell DCI baseline at 78% accuracy with gpt-5.4-mini at roughly one quarter of the per-query cost. At 1M documents, RISE-BM25 reaches 81% on gpt-5.4-mini, whereas DCI on gpt-5.4-nano degrades to 60% with 33 of 100 wall-clock failures.
We present DEI: Diversity in Evolutionary Inference, a distributed Quality-Diversity (QD) search framework that assigns heterogeneous large language models (LLMs) as mutation operators across peer nodes communicating with non-blocking collective operations. Unlike homogeneous parallel search, which replicates a single model's inductive biases across all workers, DEI treats each LLM's distinct creative prior as a complementary source of behavioral novelty. Extending the Digital Red Queen framework with DEI, nodes share local optimal solutions at the end of each round to seed the next round's population. This creates cross-model adversarial pressure that drives robustness beyond intra-model self-play. Evaluated on the Core War domain, a competitive programming benchmark in which Redcode warrior programs battle inside a simulated machine, a four-node heterogeneous ensemble (GPT-5.4-mini, Claude Sonnet 4.6, GPT-5.2, and Claude Haiku 4.5) achieves 124 percent higher merged-archive QD-Score (45.90 vs. 20.46) and 28 percent higher coverage (80.6 percent vs. 63.0 percent of cells) than a single-node baseline at equal total LLM-call budget. The heterogeneous ensemble also outperforms an equally-budgeted homogeneous ensemble on QD-Score, coverage, and held-out solution generality across all four model families. These results provide the first empirical evidence that model diversity, not merely parallelism, is the key driver of gain in distributed LLM-based QD search.
Models | OpenAI API ChatGPT Home API Docs Guides and concepts for the OpenAI API API reference Endpoints, parameters, and responses Codex Docs Guides, concepts, and product docs for Codex Use cases Example workflows and tasks teams can take on with ChatGPT or Codex Docs Use cases Resources ChatGPT Apps SDK Build apps to extend ChatGPT Workspace Agents Trigger published ChatGPT workspace agents Commerce Build commerce flows in ChatGPT Ads Publish and measure ads in ChatGPT Res
Introducing GPT-5.2 | OpenAI Skip to main content Research Products Business Developers Company Foundation (opens in a new window) Log in Try ChatGPT (opens in a new window) Research Products Business Developers Company Foundation (opens in a new window) Try ChatGPT (opens in a new window) Login OpenAI December 11, 2025 Product Release Introducing GPT‑5.2 The most advanced frontier model for professional work and long-running agents. Loading… Share Model performance Model per