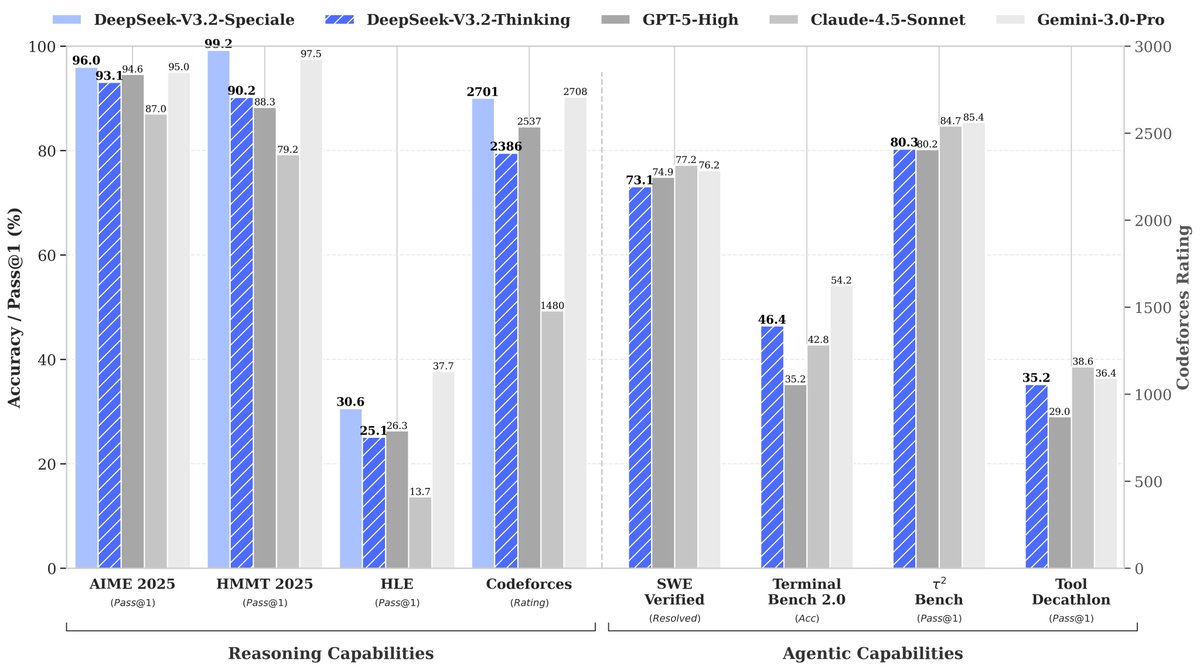
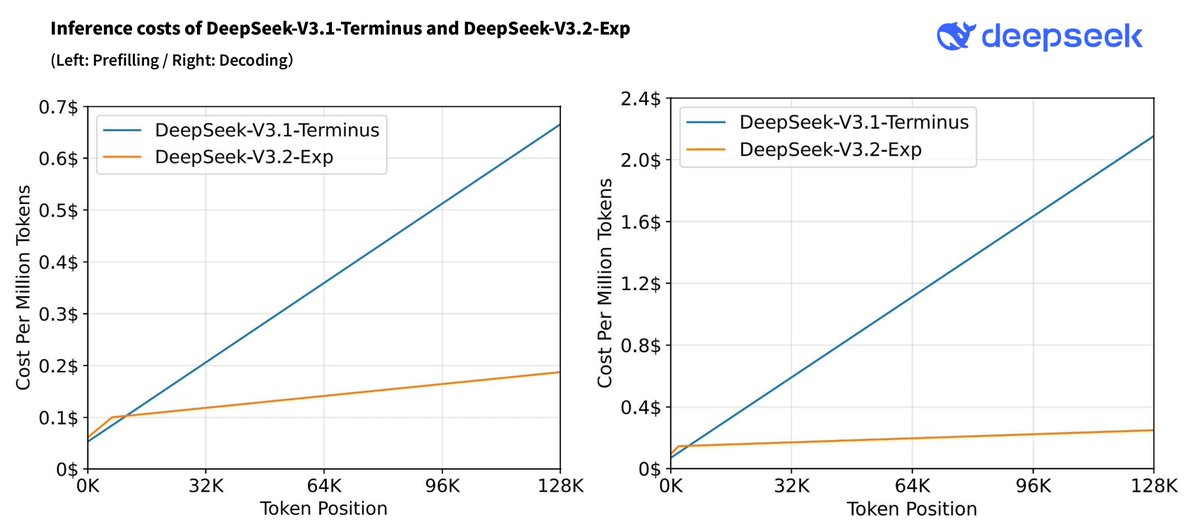
DeepSeek-V3.2 is a large language model designed to harmonize high computational efficiency with strong reasoning and agentic tool-use performance. It introduces DeepSeek Sparse Attention (DSA), a fine-grained sparse attention mechanism...
Running this yourself: can likely run on your own machine.
Model updates refreshed34m agoJul 5, 2026news + changelog
Recent launch, pricing, benchmark, and API signals linked to this model or its provider.
LaunchesDeepSeek7mo ago
🚀 Launching DeepSeek-V3.2 & DeepSeek-V3.2-Speciale — Reasoning-first models built for agents! 🔹 DeepSeek-V3.2: Official successor to V3.2-Exp. Now live on App, Web & API. 🔹 DeepSeek-V3.2-Speciale:
🚀 Launching DeepSeek-V3.2 & DeepSeek-V3.2-Speciale — Reasoning-first models built for agents! 🔹 DeepSeek-V3.2: Official successor to V3.2-Exp. Now live on App, Web & API. 🔹 DeepSeek-V3.2-Speciale: Pushing the boundaries of reasoning capabilities. API-only for now. 📄 Tech https://t.co/SC49UdmCZv
Introducing DeepSeek-V3.1: our first step toward the agent era! 🚀 🧠 Hybrid inference: Think & Non-Think — one model, two modes ⚡️ Faster thinking: DeepSeek-V3.1-Think reaches answers in less time vs
Introducing DeepSeek-V3.1: our first step toward the agent era! 🚀 🧠 Hybrid inference: Think & Non-Think — one model, two modes ⚡️ Faster thinking: DeepSeek-V3.1-Think reaches answers in less time vs. DeepSeek-R1-0528 🛠️ Stronger agent skills: Post-training boosts tool use and
🚀 Launching DeepSeek-V3.2 & DeepSeek-V3.2-Speciale — Reasoning-first models built for agents! 🔹 DeepSeek-V3.2: Official successor to V3.2-Exp. Now live on App, Web & API. 🔹 DeepSeek-V3.2-Speciale:
🚀 Launching DeepSeek-V3.2 & DeepSeek-V3.2-Speciale — Reasoning-first models built for agents! 🔹 DeepSeek-V3.2: Official successor to V3.2-Exp. Now live on App, Web & API. 🔹 DeepSeek-V3.2-Speciale: Pushing the boundaries of reasoning capabilities. API-only for now. 📄 Tech https://t.co/SC49UdmCZv
Introducing DeepSeek-V3.1: our first step toward the agent era! 🚀 🧠 Hybrid inference: Think & Non-Think — one model, two modes ⚡️ Faster thinking: DeepSeek-V3.1-Think reaches answers in less time vs
Introducing DeepSeek-V3.1: our first step toward the agent era! 🚀 🧠 Hybrid inference: Think & Non-Think — one model, two modes ⚡️ Faster thinking: DeepSeek-V3.1-Think reaches answers in less time vs. DeepSeek-R1-0528 🛠️ Stronger agent skills: Post-training boosts tool use and
VibeThinker-3B: Exploring the Frontier of Verifiable Reasoning in Small Language Models
This technical report introduces VibeThinker-3B, a compact dense model with 3B parameters developed to investigate how far verifiable reasoning can be pushed within a strictly small-model regime. Building upon the Spectrum-to-Signal post-training paradigm, we systematically enhance the model through an optimized pipeline that includes curriculum-based supervised fine-tuning, multi-domain reinforcement learning, and offline self-distillation. Experimental evaluations demonstrate that VibeThinker-3B achieves frontier-level performance on highly demanding verifiable tasks. Specifically, it attains a score of 94.3 on AIME26 (improving to 97.1 with claim-level test-time scaling), an 80.2 Pass@1 on LiveCodeBench v6, and exhibits strong out-of-distribution generalization with a 96.1\% acceptance rate on recent unseen LeetCode contests. This effectively places it in the performance band of first-tier reasoning systems, matching or exceeding flagship models that are orders of magnitude larger, such as DeepSeek V3.2, GLM-5, and Gemini 3 Pro. Furthermore, a score of 93.4 on IFEval confirms that this extreme reasoning enhancement does not compromise strict instruction controllability. Extending our previous 1.5B work, these findings motivate the Parametric Compression-Coverage Hypothesis, which views verifiable reasoning as compressible into compact reasoning cores, while open-domain knowledge and general-purpose competence require broad parameter coverage over facts, concepts, and long-tail scenarios. This perspective suggests that compact models are not merely deployment-efficient substitutes, but a complementary path toward frontier-level performance in parameter-dense capability regimes.
EEVEE: Towards Test-time Prompt Learning in the Real World for Self-Improving Agents
In this paper, we propose EEVEE, the first multi-dataset test-time prompt learning framework for LLM agents, enabling test-time prompt learning under real-world task streams. Existing methods are largely designed for single-dataset settings, while real-world applications require models to handle heterogeneous input streams drawn from multiple datasets, domains, and task distributions, limiting their practical applicability. To mitigate cross-dataset interference, EEVEE introduces a router that partitions incoming inputs into task clusters and assigns them to suitable prompt configurations. This design is optimized via a router-prompt co-evolution strategy, which employs interleaved router and prompt learning phases to address their mutual dependency. Experiments across multiple datasets demonstrate that the framework improves robustness under heterogeneous data streams while maintaining single-benchmark learning capability and efficiency. Specifically, EEVEE improves average multi-benchmark scores by 10.38 and 24.32 points over Qwen3-4B-Instruct and DeepSeek-V3.2, surpassing SOTA methods GEPA and ACE by up to 37.2% and 48.2%.
Precise Debugging Benchmark: Is Your Model Debugging or Regenerating?
Unlike code completion, debugging requires localizing faults and applying targeted edits. We observe that frontier LLMs often regenerate correct but over-edited solutions during debugging. To evaluate how far LLMs are from precise debugging, we introduce the Precise Debugging Benchmark (PDB) framework, which automatically converts any coding dataset into a debugging benchmark with precision-aware evaluation. PDB generates buggy programs by synthesizing verified atomic bugs and composing them into multi-bug programs. We define two novel metrics, edit-level precision and bug-level recall, which measures how many necessary edits are made and how many bugs are resolved. We release two evaluation benchmarks: PDB-Single-Hard on single-line bugs, and PDB-Multi on multi-line bugs. Experiments show that frontier models, such as GPT-5.1-Codex and DeepSeek-V3.2-Thinking, achieve unit-test pass rates above 76% but exhibit precision below 45%, even when explicitly instructed to perform minimal debugging. Finally, we show that iterative and agentic debugging strategies do not substantially improve precision or recall, highlighting the need to rethink post-training pipelines for coding models.
SPASM: Stable Persona-driven Agent Simulation for Multi-turn Dialogue Generation
Large language models are increasingly deployed in multi-turn settings such as tutoring, support, and counseling, where reliability depends on preserving consistent roles, personas, and goals across long horizons. This requirement becomes critical when LLMs are used to generate synthetic dialogues for training and evaluation, since LLM--LLM conversations can accumulate identity-related failures such as persona drift, role confusion, and "echoing", where one agent gradually mirrors its partner. We introduce SPASM (Stable Persona-driven Agent Simulation for Multi-turn dialogue generation), a modular, stability-first framework that decomposes simulation into (i) persona creation via schema sampling, plausibility validation, and natural-language persona crafting, (ii) Client--Responder dialogue generation, and (iii) termination detection for coherent stopping. To improve long-horizon stability without changing model weights, we propose Egocentric Context Projection (ECP): dialogue history is stored in a perspective-agnostic representation and deterministically projected into each agent's egocentric view before generation. Across three LLM backbones (GPT-4o-mini, DeepSeek-V3.2, Qwen-Plus) and nine Client--Responder pairings, we construct a dataset of 4,500 personas and 45,000 conversations (500 personas X 10 conversations per pairing). Ablations show ECP substantially reduces persona drift and, under human validation, eliminates echoing; embedding analyses recover persona structure and reveal strong responder-driven interaction geometry. Our code is available at https://github.com/lhannnn/SPASM.
HISA: Efficient Hierarchical Indexing for Fine-Grained Sparse Attention
Token-level sparse attention mechanisms, exemplified by DeepSeek Sparse Attention (DSA), achieve fine-grained key selection by scoring every historical token for each query using a lightweight indexer, and then computing attention only over the selected subset. While the downstream sparse attention scales efficiently, the indexer still scans the entire prefix for every query, introducing an O(L^2) per-layer bottleneck that becomes prohibitive as context length grows. We propose HISA (Hierarchical Indexed Sparse Attention), a drop-in replacement for the indexer that transforms the search process from a flat token scan into a two-stage hierarchical procedure. First, a block-level coarse filter scores pooled block representatives to prune irrelevant regions. Then, a token-level refinement applies the original indexer only within the remaining candidate blocks. HISA preserves the exact token-level top-k sparsity pattern required by the downstream Sparse MLA operator and requires no additional training. On kernel-level benchmarks, HISA achieves a 2times speedup at 32K context length and 4times at 128K. On Needle-in-a-Haystack and LongBench, we directly replace the indexer in DeepSeek-V3.2 with HISA, without any fine-tuning. HISA closely matches the original DSA in quality while significantly outperforming block-sparse baselines. Moreover, the token selection sets produced by HISA and the original DSA exhibit a mean IoU greater than 99%, indicating that the efficiency gains come with virtually no impact on selection fidelity.
Kernel-Smith: A Unified Recipe for Evolutionary Kernel Optimization
We present Kernel-Smith, a framework for high-performance GPU kernel and operator generation that combines a stable evaluation-driven evolutionary agent with an evolution-oriented post-training recipe. On the agent side, Kernel-Smith maintains a population of executable candidates and iteratively improves them using an archive of top-performing and diverse programs together with structured execution feedback on compilation, correctness, and speedup. To make this search reliable, we build backend-specific evaluation services for Triton on NVIDIA GPUs and Maca on MetaX GPUs. On the training side, we convert long-horizon evolution trajectories into step-centric supervision and reinforcement learning signals by retaining correctness-preserving, high-gain revisions, so that the model is optimized as a strong local improver inside the evolutionary loop rather than as a one-shot generator. Under a unified evolutionary protocol, Kernel-Smith-235B-RL achieves state-of-the-art overall performance on KernelBench with Nvidia Triton backend, attaining the best average speedup ratio and outperforming frontier proprietary models including Gemini-3.0-pro and Claude-4.6-opus. We further validate the framework on the MetaX MACA backend, where our Kernel-Smith-MACA-30B surpasses large-scale counterparts such as DeepSeek-V3.2-think and Qwen3-235B-2507-think, highlighting potential for seamless adaptation across heterogeneous platforms. Beyond benchmark results, the same workflow produces upstream contributions to production systems including SGLang and LMDeploy, demonstrating that LLM-driven kernel optimization can transfer from controlled evaluation to practical deployment.
GSEM: Graph-based Self-Evolving Memory for Experience Augmented Clinical Reasoning
Clinical decision-making agents can benefit from reusing prior decision experience. However, many memory-augmented methods store experiences as independent records without explicit relational structure, which may introduce noisy retrieval, unreliable reuse, and in some cases even hurt performance compared to direct LLM inference. We propose GSEM (Graph-based Self-Evolving Memory), a clinical memory framework that organizes clinical experiences into a dual-layer memory graph, capturing both the decision structure within each experience and the relational dependencies across experiences, and supporting applicability-aware retrieval and online feedback-driven calibration of node quality and edge weights. Across MedR-Bench and MedAgentsBench with two LLM backbones, GSEM achieves the highest average accuracy among all baselines, reaching 70.90\% and 69.24\% with DeepSeek-V3.2 and Qwen3.5-35B, respectively. Code is available at https://github.com/xhan1022/gsem.
Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation
We introduce Nemotron-Cascade 2, an open 30B MoE model with 3B activated parameters that delivers best-in-class reasoning and strong agentic capabilities. Despite its compact size, its mathematical and coding reasoning performance approaches that of frontier open models. It is the second open-weight LLM, after DeepSeekV3.2-Speciale-671B-A37B, to achieve Gold Medal-level performance in the 2025 International Mathematical Olympiad (IMO), the International Olympiad in Informatics (IOI), and the ICPC World Finals, demonstrating remarkably high intelligence density with 20x fewer parameters. In contrast to Nemotron-Cascade 1, the key technical advancements are as follows. After SFT on a meticulously curated dataset, we substantially expand Cascade RL to cover a much broader spectrum of reasoning and agentic domains. Furthermore, we introduce multi-domain on-policy distillation from the strongest intermediate teacher models for each domain throughout the Cascade RL process, allowing us to efficiently recover benchmark regressions and sustain strong performance gains along the way. We release the collection of model checkpoint and training data.
Nemotron-Cascade 2: Post-Training LLMs with Cascade RL and Multi-Domain On-Policy Distillation
We introduce Nemotron-Cascade 2, an open 30B MoE model with 3B activated parameters that delivers best-in-class reasoning and strong agentic capabilities. Despite its compact size, its mathematical and coding reasoning performance approaches that of frontier open models. It is the second open-weight LLM, after DeepSeekV3.2-Speciale-671B-A37B, to achieve Gold Medal-level performance in the 2025 International Mathematical Olympiad (IMO), the International Olympiad in Informatics (IOI), and the ICPC World Finals, demonstrating remarkably high intelligence density with 20x fewer parameters. In contrast to Nemotron-Cascade 1, the key technical advancements are as follows. After SFT on a meticulously curated dataset, we substantially expand Cascade RL to cover a much broader spectrum of reasoning and agentic domains. Furthermore, we introduce multi-domain on-policy distillation from the strongest intermediate teacher models for each domain throughout the Cascade RL process, allowing us to efficiently recover benchmark regressions and sustain strong performance gains along the way. We release the collection of model checkpoint and training data.
DeepSeek V3.2 is now available through Ollama Cloud. 160K context window listed. DeepSeek-V3.2, a model that harmonizes high computational efficiency with superior reasoning and agent performance.