LaunchesDeepSeek2mo ago
X/Twitter@deepseek_aiDeepSeekpricingpricing9mo ago
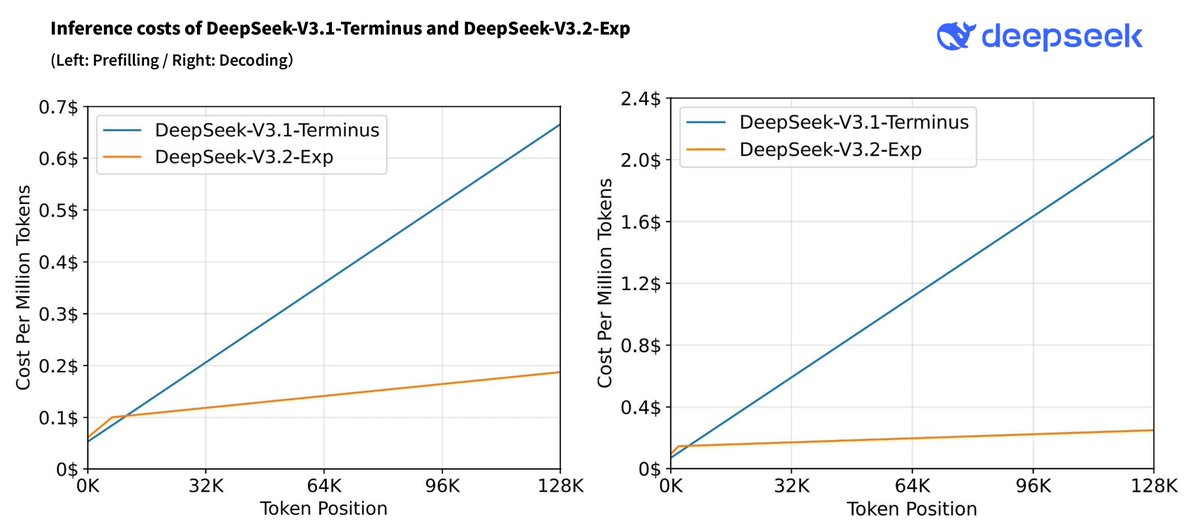
⚡️ Efficiency Gains 🤖 DSA achieves fine-grained sparse attention with minimal impact on output quality — boosting long-context performance & reducing compute cost. 📊 Benchmarks show V3.2-Exp perform
⚡️ Efficiency Gains 🤖 DSA achieves fine-grained sparse attention with minimal impact on output quality — boosting long-context performance & reducing compute cost. 📊 Benchmarks show V3.2-Exp performs on par with V3.1-Terminus. 2/n https://t.co/zTG679p5Zm
View Post
#deepseek#twitter#x