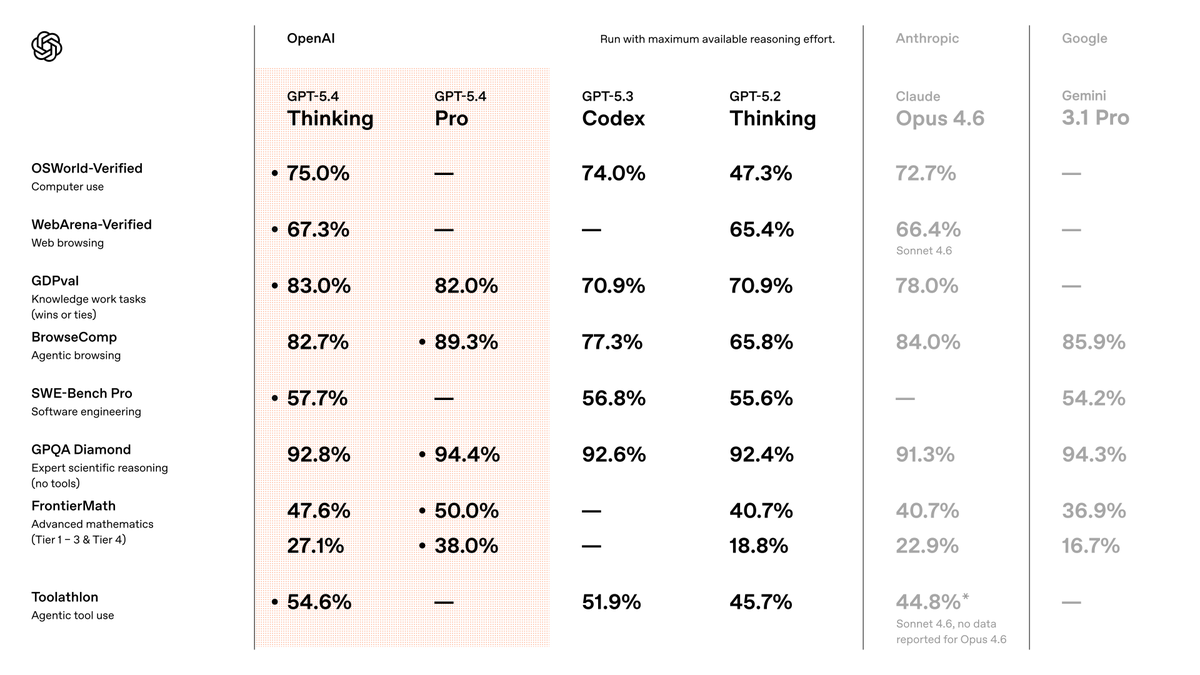
Introducing GPT-5.4 | OpenAI Skip to main content Research Products Business Developers Company Foundation (opens in a new window) Log in Try ChatGPT (opens in a new window) Research Products Business Developers Company Foundation (opens in a new window) Try ChatGPT (opens in a new window) Login OpenAI March 5, 2026 Product Release Introducing GPT‑5.4 Designed for professional work Loading… Share Knowledge work Knowledge work Computer use and vision Coding Tool use Tool searc
We’re sharing new research on a method for anticipating how models may behave in real-world use before release: simulating deployment with recent, de-identified user requests and studying candidate mo
We’re sharing new research on a method for anticipating how models may behave in real-world use before release: simulating deployment with recent, de-identified user requests and studying candidate model responses. https://t.co/7RJzBfNniQ
GPT-5.4 Thinking and GPT-5.4 Pro are rolling out now in ChatGPT. GPT-5.4 is also now available in the API and Codex. GPT-5.4 brings our advances in reasoning, coding, and agentic workflows into one fr
GPT-5.4 Thinking and GPT-5.4 Pro are rolling out now in ChatGPT. GPT-5.4 is also now available in the API and Codex. GPT-5.4 brings our advances in reasoning, coding, and agentic workflows into one frontier model. https://t.co/1hy6xXLAmJ
Introducing GPT-5.4 | OpenAI Skip to main content Research Products Business Developers Company Foundation (opens in a new window) Log in Try ChatGPT (opens in a new window) Research Products Business Developers Company Foundation (opens in a new window) Try ChatGPT (opens in a new window) Login OpenAI March 5, 2026 Product Release Introducing GPT‑5.4 Designed for professional work Loading… Share Knowledge work Knowledge work Computer use and vision Coding Tool use Tool searc
OpenAI DevDay 2026 applications are now open! Our biggest developer event gets even bigger. 📍 San Francisco 📅 September 29 Apply by July 10: https://t.co/BJyK2EbKuu
As AI takes on longer, higher-stakes tasks, we want models to carry beneficial and safe behavior into new domains beyond their training—and maintain it under pressure. That’s the idea behind our new r
As AI takes on longer, higher-stakes tasks, we want models to carry beneficial and safe behavior into new domains beyond their training—and maintain it under pressure. That’s the idea behind our new research on training models to be broadly and persistently beneficial.
Introducing LifeSciBench, a benchmark for measuring and improving how well AI supports real-world life science research. Developed with 173 scientists from biotechnology and pharmaceutical research, L
Introducing LifeSciBench, a benchmark for measuring and improving how well AI supports real-world life science research. Developed with 173 scientists from biotechnology and pharmaceutical research, LifeSciBench includes 750 expert-authored tasks across seven biological research https://t.co/JDkKWcnL9F
We’re sharing new research on a method for anticipating how models may behave in real-world use before release: simulating deployment with recent, de-identified user requests and studying candidate mo
We’re sharing new research on a method for anticipating how models may behave in real-world use before release: simulating deployment with recent, de-identified user requests and studying candidate model responses. https://t.co/7RJzBfNniQ
Let’s talk about evals. We’re always looking for better ways to measure and forecast model progress, especially as benchmarks get saturated or gamed. @tejalpatwardhan, who leads our frontier evals tea
Let’s talk about evals. We’re always looking for better ways to measure and forecast model progress, especially as benchmarks get saturated or gamed. @tejalpatwardhan, who leads our frontier evals team, spoke to @andrewmayne about why evals matter and what models need to be https://t.co/Q3oRCuNxYB
GPT-5.4 Thinking and GPT-5.4 Pro are rolling out now in ChatGPT. GPT-5.4 is also now available in the API and Codex. GPT-5.4 brings our advances in reasoning, coding, and agentic workflows into one fr
GPT-5.4 Thinking and GPT-5.4 Pro are rolling out now in ChatGPT. GPT-5.4 is also now available in the API and Codex. GPT-5.4 brings our advances in reasoning, coding, and agentic workflows into one frontier model. https://t.co/1hy6xXLAmJ
S-Agent: Spatial Tool-Use Elicits Reasoning for Spatial Intelligence
Real-world spatial intelligence requires reasoning over a continuous and evolving 3D world, yet existing VLMs and tool-augmented agents largely remain tied to static, stateless inference from isolated visual observations. We introduce \textsc{S-Agent}, a spatial tool-use agentic paradigm for understanding and reasoning over continuous multi-view images and videos. By formulating spatial reasoning as spatio-temporal evidence accumulation rather than isolated frame-level prediction, S-Agent reshapes spatial perception into scene-centric understanding beyond frame-centric recognition. Specifically, S-Agent casts the VLM as a semantic planner that decides what evidence is needed, while a hierarchy of spatial tools and experts grounds objects in 2D, lifts them into 3D geometric evidence, and aggregates this evidence into high-level spatial knowledge (e.g., counting, measurement, orientation, and relative position). Additionally, a temporal memory mechanism, including Scene Memory for maintaining the evolving scene state and Agent Memory for accumulating reasoning context, enables evidence integration across frames and reasoning steps. Comprehensive experiments on multi-view and video spatial reasoning benchmarks show that S-Agent consistently improves both open-source and closed-source VLMs in a training-free manner. Beyond inference-time augmentation, supervised fine-tuning (SFT) on S-Agent-generated spatial trajectories S-300K yields S-Agent-8B, a compact spatial agent that significantly surpasses similar-scale baselines (e.g., Qwen3-VL-8B) and performs comparably to advanced closed-source models (e.g., GPT-5.4 and Gemini 3).
Multi-agent reasoning systems adopt a "generate-then-transfer" paradigm that forces end-to-end latency to scale linearly with pipeline depth. We introduce StreamMA, a multi-agent reasoning system that streams each reasoning step to downstream agents as soon as it is generated, pipelining adjacent agents and thus reducing latency. Surprisingly, this pipelining also improves effectiveness: because multi-step reasoning quality is non-uniform and early steps are more reliable than later ones, working with these reliable early steps instead of the full chain prevents error-prone late steps from misleading downstream agents. We formalize both advantages with the first closed-form joint analysis of stream, serial, and single protocols, deriving the effectiveness ordering, speedup upper bound, and cost ratio. Across eight reasoning benchmarks spanning mathematics, science, and code, two frontier LLMs (Claude Opus 4.6 and GPT-5.4), and three topologies (Chain, Tree, Graph), StreamMA outperforms both baselines (avg. +7.3 pp, max +22.4 pp on HMMT 2026; Claude Opus 4.6-high). Beyond these contributions, we discover a "step-level scaling law": increasing per-agent steps consistently improves both effectiveness and efficiency, a new scaling dimension orthogonal to and composable with agent-count scaling.
CurveBench: A Benchmark for Exact Topological Reasoning over Nested Jordan Curves
We introduce CurveBench, a benchmark for hierarchical topological reasoning from visual input. CurveBench consists of 756 images of pairwise non-intersecting Jordan curves across easy, polygonal, topographic-inspired, maze-like, and dense counting configurations. Each image is annotated with a rooted tree encoding the containment relations between planar regions. We formulate the task as structured prediction: given an image, a model must recover the full rooted containment tree induced by the curves. Despite the visual simplicity of the task, the strongest evaluated model, Gemini 3.1 Pro, achieves only 71.1\% tree-generation accuracy on CurveBench-Easy and 19.1\% on CurveBench-Hard. We further demonstrate benchmark utility through RLVR-style fine-tuning of open-weight vision-language models. Our trained Qwen3-VL-8B model improves over Qwen-3-VL-8B-Thinking from 2.8\% to 33.3\% tree-generation accuracy on CurveBench-Easy, exceeding GPT-5.4 and Claude Opus 4.5 under our evaluation protocol. The remaining gap, especially on CurveBench-Hard, shows that exact topology-aware visual reasoning remains far from solved.
IntentGrasp: A Comprehensive Benchmark for Intent Understanding
Accurately understanding the intent behind speech, conversation, and writing is crucial to the development of helpful Large Language Model (LLM) assistants. This paper introduces IntentGrasp, a comprehensive benchmark for evaluating the intent understanding capability of LLMs. Derived from 49 high-quality, open-licensed corpora spanning 12 diverse domains, IntentGrasp is constructed through source datasets curation, intent label contextualization, and task format unification. IntentGrasp contains a large-scale training set of 262,759 instances and two evaluation sets: an All Set of 12,909 test cases and a more balanced and challenging Gem Set of 470 cases. Extensive evaluations on 20 LLMs across 7 families (including frontier models such as GPT-5.4, Gemini-3.1-Pro, and Claude-Opus-4.7) demonstrate unsatisfactory performance, with scores below 60% on All Set and below 25% on Gem set. Notably, 17 out of 20 tested models perform worse than a random-guess baseline (15.2%) on Gem Set, while the estimated human performance is ~81.1%, showing substantial room for improvement. To enhance such ability, this paper proposes Intentional Fine-Tuning (IFT), which fine-tunes the models on the training set in IntentGrasp, yielding significant gains of 30+ F1 points on All Set and 20+ points on Gem Set. Tellingly, the leave-one-domain-out (Lodo) experiments further demonstrate the strong cross-domain generalizability of IFT, verifying that it is a promising approach to substantially enhancing the intent understanding of LLMs. Overall, by benchmarking and boosting intent understanding ability, this study sheds light on a promising path towards more intentional, capable, and safe AI assistants for human benefits and social good.
Playing Along: Learning a Double-Agent Defender for Belief Steering via Theory of Mind
As large language models (LLMs) become the engine behind conversational systems, their ability to reason about the intentions and states of their dialogue partners (i.e., form and use a theory-of-mind, or ToM) becomes increasingly critical for safe interaction with potentially adversarial partners. We propose a novel privacy-themed ToM challenge, ToM for Steering Beliefs (ToM-SB), in which a defender must act as a Double Agent to steer the beliefs of an attacker with partial prior knowledge within a shared universe. To succeed on ToM-SB, the defender must engage with and form a ToM of the attacker, with a goal of fooling the attacker into believing they have succeeded in extracting sensitive information. We find that strong frontier models like Gemini3-Pro and GPT-5.4 struggle on ToM-SB, often failing to fool attackers in hard scenarios with partial attacker prior knowledge, even when prompted to reason about the attacker's beliefs (ToM prompting). To close this gap, we train models on ToM-SB to act as AI Double Agents using reinforcement learning, testing both fooling and ToM rewards. Notably, we find a bidirectionally emergent relationship between ToM and attacker-fooling: rewarding fooling success alone improves ToM, and rewarding ToM alone improves fooling. Across four attackers with different strengths, six defender methods, and both in-distribution and out-of-distribution (OOD) evaluation, we find that gains in ToM and attacker-fooling are well-correlated, highlighting belief modeling as a key driver of success on ToM-SB. AI Double Agents that combine both ToM and fooling rewards yield the strongest fooling and ToM performance, outperforming Gemini3-Pro and GPT-5.4 with ToM prompting on hard scenarios. We also show that ToM-SB and AI Double Agents can be extended to stronger attackers, demonstrating generalization to OOD settings and the upgradability of our task.
HorizonMath: Measuring AI Progress Toward Mathematical Discovery with Automatic Verification
Can AI make progress on important, unsolved mathematical problems? Large language models are now capable of sophisticated mathematical and scientific reasoning, but whether they can perform novel research is still widely debated and underexplored. We introduce HorizonMath, a benchmark of over 100 predominantly unsolved problems spanning 8 domains in computational and applied mathematics, paired with an open-source evaluation framework for automated verification. Our benchmark targets a class of problems where discovery is hard, requiring meaningful mathematical insight, but verification is computationally efficient and simple. Because these solutions are unknown, HorizonMath is immune to data contamination, and most state-of-the-art models score near 0%. Existing research-level benchmarks instead rely on formal proof verification or manual review, both of which are expensive to scale. Using this platform, we find two problems for which GPT 5.4 Pro proposes solutions that improve on the best-known published results, representing potential novel contributions (pending expert review). We release HorizonMath as an open challenge and a growing community resource, where correct solutions to problems in the unsolved problem classes could constitute novel results in the mathematical literature.
HorizonMath: Measuring AI Progress Toward Mathematical Discovery with Automatic Verification
Can AI make progress on important, unsolved mathematical problems? Large language models are now capable of sophisticated mathematical and scientific reasoning, but whether they can perform novel research is still widely debated and underexplored. We introduce HorizonMath, a benchmark of over 100 predominantly unsolved problems spanning 8 domains in computational and applied mathematics, paired with an open-source evaluation framework for automated verification. Our benchmark targets a class of problems where discovery is hard, requiring meaningful mathematical insight, but verification is computationally efficient and simple. Because these solutions are unknown, HorizonMath is immune to data contamination, and most state-of-the-art models score near 0%. Existing research-level benchmarks instead rely on formal proof verification or manual review, both of which are expensive to scale. Using this platform, we find two problems for which GPT 5.4 Pro proposes solutions that improve on the best-known published results, representing potential novel contributions (pending expert review). We release HorizonMath as an open challenge and a growing community resource, where correct solutions to problems in the unsolved problem classes could constitute novel results in the mathematical literature.
Introducing GPT‑5 for developers | OpenAI Skip to main content Research Products Business Developers Company Foundation (opens in a new window) Log in Try ChatGPT (opens in a new window) Research Products Business Developers Company Foundation (opens in a new window) Try ChatGPT (opens in a new window) Login OpenAI August 7, 2025 Product Introducing GPT‑5 for developers The best model for coding and agentic tasks. Loading… Share Introduction Introduction Coding Frontend engin