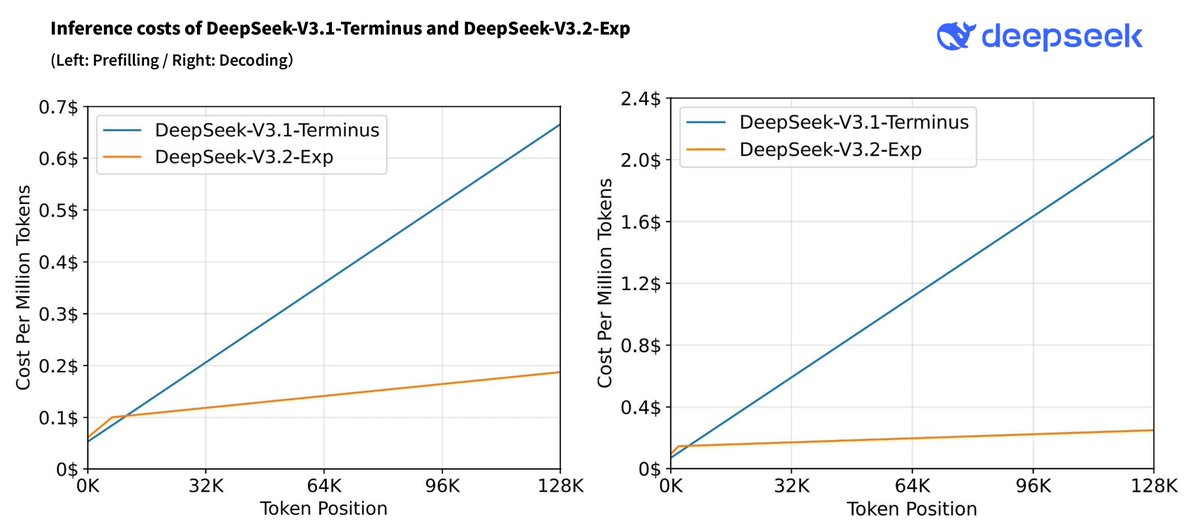
🚀 Introducing DeepSeek-V3.2-Exp — our latest experimental model! ✨ Built on V3.1-Terminus, it debuts DeepSeek Sparse Attention(DSA) for faster, more efficient training & inference on long context. 👉 Now live on App, Web, and API. 💰 API prices cut by 50%+! 1/n
Explainable AI (XAI) research has experienced substantial growth in recent years. Existing XAI methods, however, have been criticized for being technical and expert-oriented, motivating the development of more interpretable and accessible explanations. In response, large language model (LLM)-generated XAI narratives have been proposed as a promising approach for translating post-hoc explanations into more accessible, natural-language explanations. In this work, we propose a multi-agent framework for XAI narrative generation and refinement. The framework comprises the Narrator, which generates and revises narratives based on feedback from multiple Critic Agents on faithfulness and coherence metrics, thereby enabling narrative improvement through iteration. We design five agentic systems (Basic Design, Critic Design, Critic-Rule Design, Coherent Design, and Coherent-Rule Design) and systematically evaluate their effectiveness across five LLMs on five tabular datasets. Results validate that the Basic Design, the Critic Design, and the Critic-Rule Design are effective in improving the faithfulness of narratives across all LLMs. Claude-4.5-Sonnet on Basic Design performs best, reducing the number of unfaithful narratives by 90% after three rounds of iteration. To address recurrent issues, we further introduce an ensemble strategy based on majority voting. This approach consistently enhances performance for four LLMs, except for DeepSeek-V3.2-Exp. These findings highlight the potential of agentic systems to produce faithful and coherent XAI narratives.